Optimizing Response Generation
The Generation Optimization tab empowers you to refine how your application produces AI-generated responses. Through systematic testing of language models and configurations, you can identify the optimal setup for creating accurate, relevant, and well-crafted outputs tailored to your specific requirements.
Understanding Generation Optimization
Response generation quality depends on several key factors:
- The foundation language model (LLM) selected
- Parameter settings like temperature and token limits
- Prompt engineering and formulation
- Fine-tuning customizations (when applicable)
The Generation Optimization tab helps you test combinations of these factors to determine which configuration produces the best results for your use case.
Foundation LLM Optimization
The first section focuses on testing pre-trained language models with various configurations:
Setting Up Foundation LLM Experiments
Unlike Retrieval Optimization, Generation experiments don't require initialization:
-
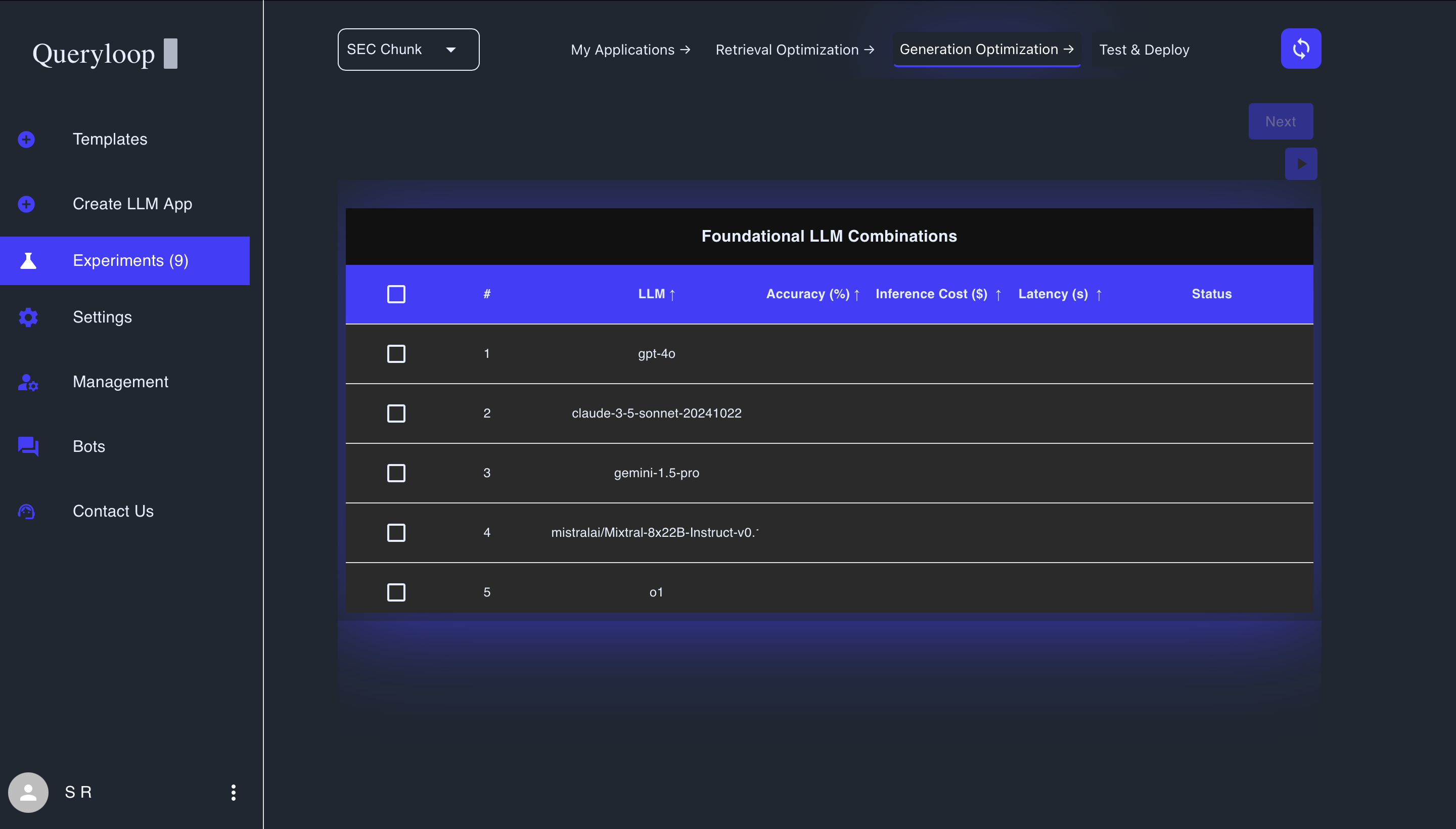
Review the available combinations in the table, which include variations of:
- Language Models: From providers like OpenAI (GPT-4o, GPT-4o-mini), Anthropic (Claude), Google (Gemini), and others
- Prompt Type: Zero-shot, few-shot, chain of thought, etc.
- Prompts: The actual system instruction provided to the model
- Temperature: Controlling creativity vs. predictability
- Token Limit: Defining maximum response length
-
Check the boxes next to combinations you want to test
- Start with diverse options to explore the solution space
- Include models from different providers for comprehensive comparison
-
Click Run Selected Combinations to begin testing
Each combination will be evaluated using your Golden QnA pairs, with results showing how effectively the configuration generates accurate and appropriate responses.
Understanding Experiment Statuses
During testing, you'll see these status indicators:
- Queued: Waiting in line for processing
- Running: Currently being evaluated
- Completed: Testing finished, results available
- Failed: Error during evaluation (check logs for details)
You can abort running experiments by clicking the Abort button if you need to make adjustments or notice issues.
Analyzing Foundation LLM Results
After experiments complete, analyze the results to identify the best performing configurations:
Key Performance Metrics
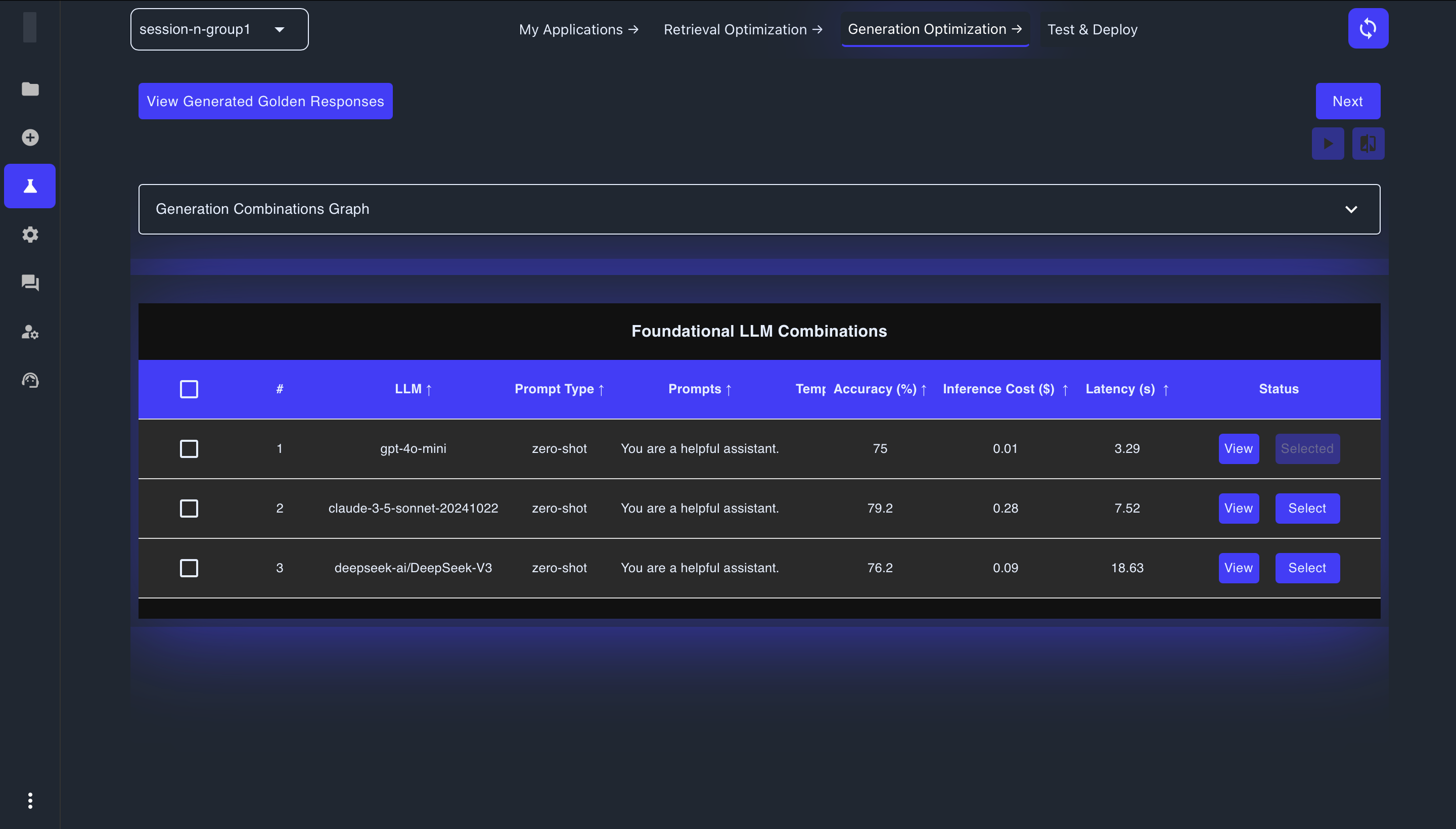
The combinations table shows several key metrics to help you evaluate performance:
- Accuracy (%): Percentage score indicating how accurately the model generates responses
- Inference Cost ($): The cost per inference in dollars
- Latency (s): Response time in seconds, indicating how quickly results are returned
- Status: Current state of the combination (Selected, Ready to select)
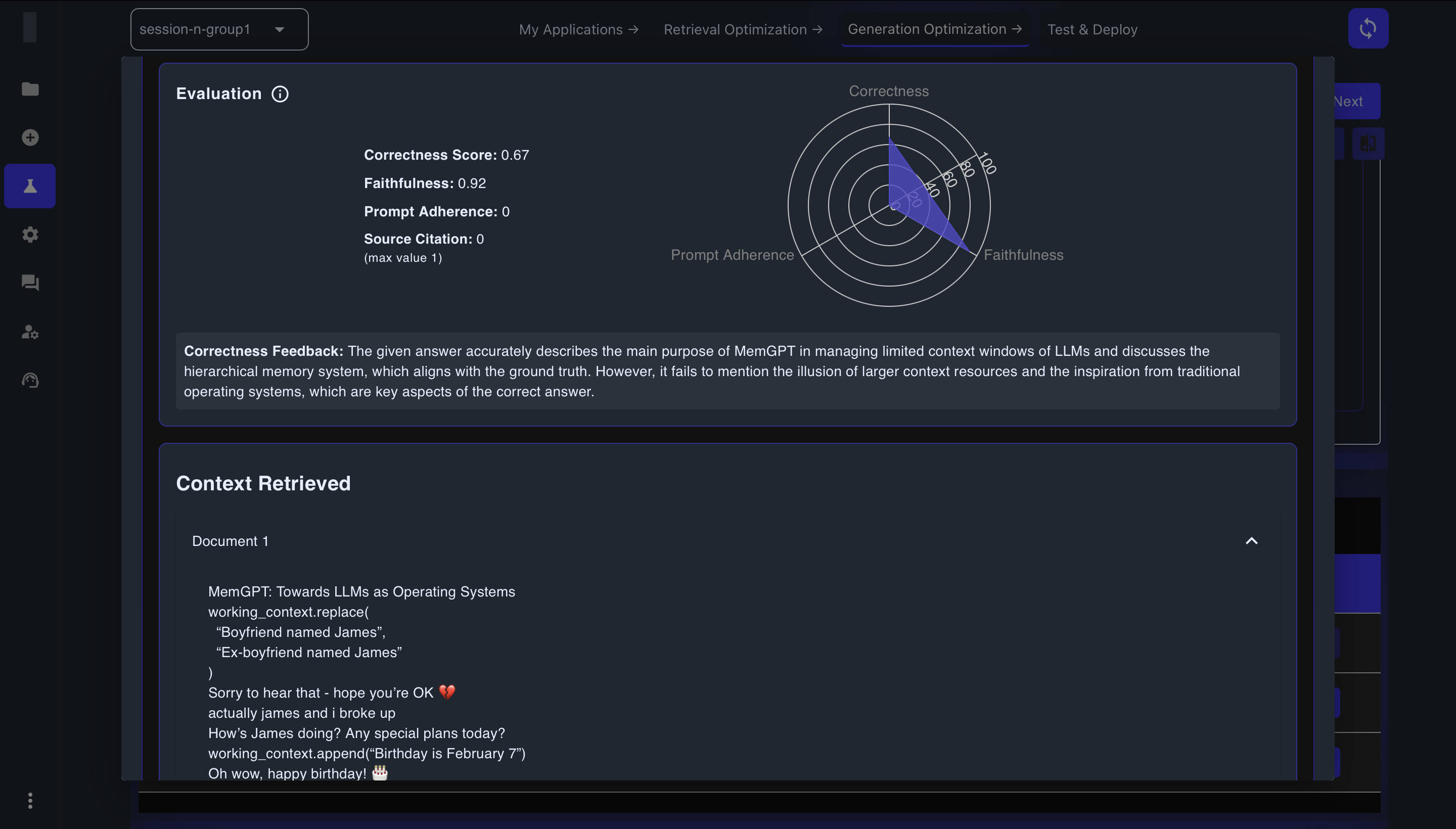
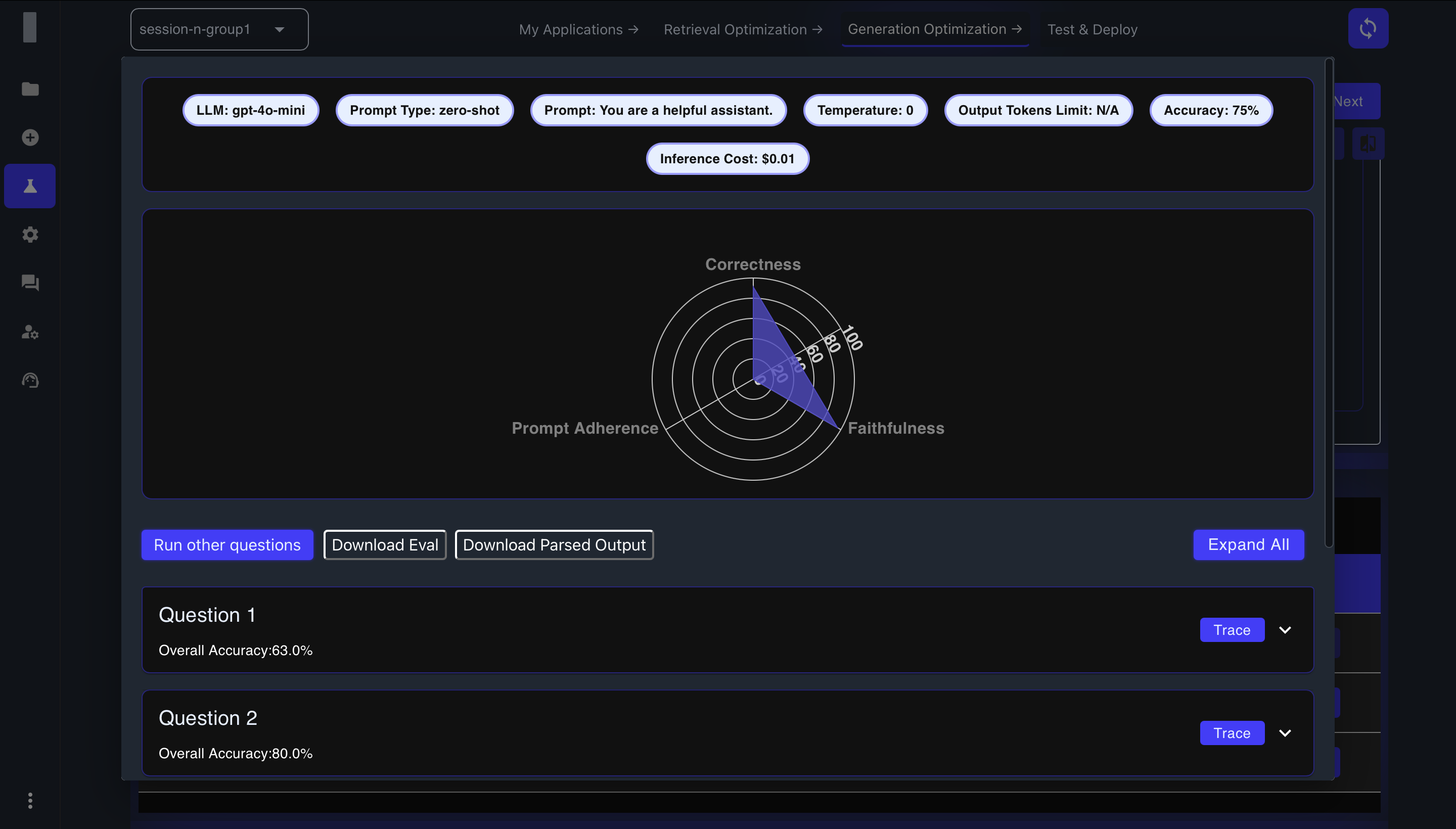
In the detailed view for each combination, you'll see a radar chart and additional metrics:
- Correctness Score: How well the response covers the information in the golden answer (0-1 scale)
- Faithfulness: How well the response sticks to the information provided in the context (0-1 scale)
- Prompt Adherence: How well the response follows the instructions provided (0-1 scale)
- Source Citation: How well sources are cited in the response (0-1 scale)
- Overall Accuracy: Percentage score for each test question
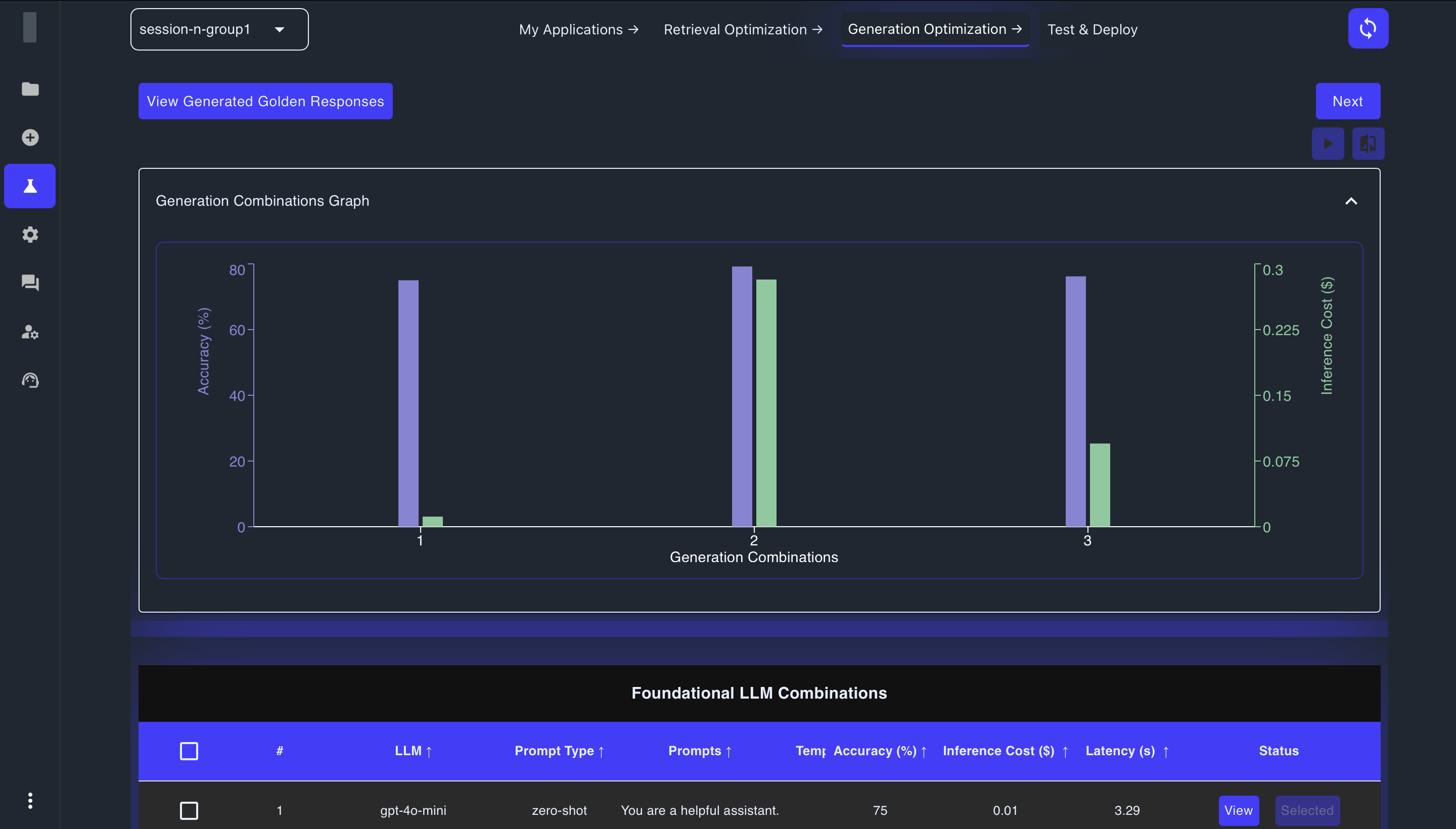
Visualization and Detailed Analysis
To gain deeper insights into your results:
-
Expand the Generation Combinations Graph to visualize metrics across configurations
-
Sort results by different metrics to identify top performers
-
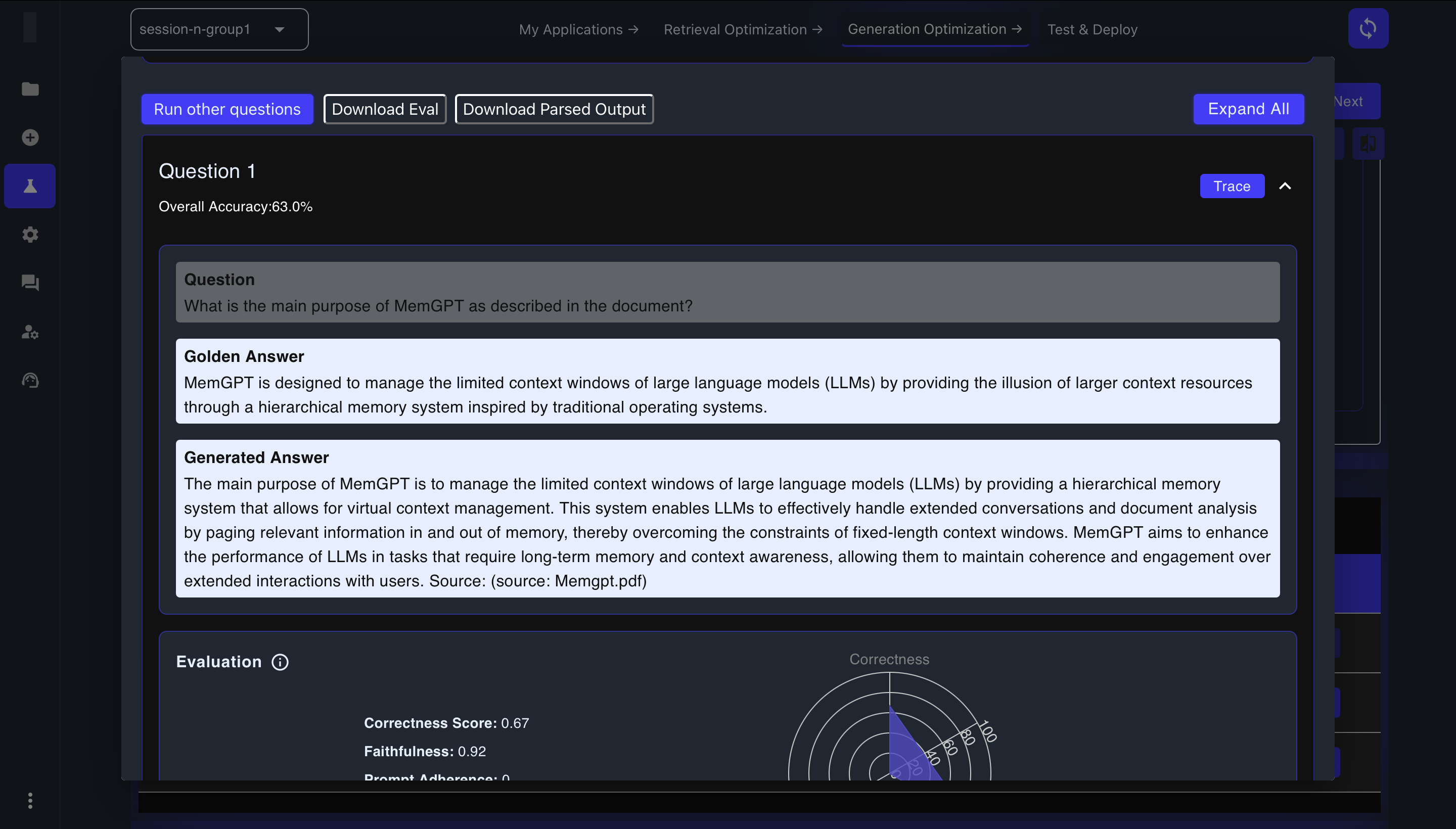
Click "View" on individual combinations to examine detailed results for each test question
-
Expand individual questions to see the golden answer, generated answer, and evaluation metrics
-
View retrieved context to understand what information was used to generate the response
-
Download evaluation results for offline analysis or documentation
Testing with Additional Questions
Beyond your Golden QnA pairs:
- Click Run Other Questions to test with custom queries
- Enter new questions to assess generalization capabilities
- Evaluate how well the configuration handles diverse question types
This additional testing helps ensure your chosen configuration performs consistently across a range of queries.
Fine-Tuning Optimization (Coming Soon)
Queryloop is currently enhancing its fine-tuning capabilities to provide you with even more powerful tools to customize language models for your specific needs. This feature will allow you to adapt pre-trained models to your unique requirements, domain-specific knowledge, and preferred response styles.
What to Expect
When released, our fine-tuning optimization will enable you to:
- Train models on your custom data
- Tailor model responses to match your specific use case
- Enhance performance for domain-specific applications
Stay tuned for updates. In the meantime, you can achieve excellent results using our foundation model optimization tools described above.
Selecting the Optimal Generation Configuration
After thorough analysis:
-
Identify the configuration that best balances:
- Response quality and accuracy
- Generation speed
- Resource utilization
- Domain specialization (for fine-tuned models)
-
Click the Select button for your chosen configuration
-
Click Next to proceed to the Test and Deploy phase
Note: You can change your selection at any time before proceeding to the next phase by selecting a different configuration.
Troubleshooting Generation Optimization
If you encounter issues during optimization:
- Poor performance: Verify that your Golden QnAs are well-formulated and representative
- Inconsistent results: Check for ambiguity in your questions or expected answers
- High latency: Consider models with lower computational requirements for time-sensitive applications
Next Steps
After selecting your optimal generation configuration:
- You'll proceed to the Test and Deploy phase to validate your application's performance in a real-world context
By systematically optimizing your generation parameters, you'll significantly enhance your application's ability to produce high-quality, contextually appropriate responses that meet or exceed your specific requirements.